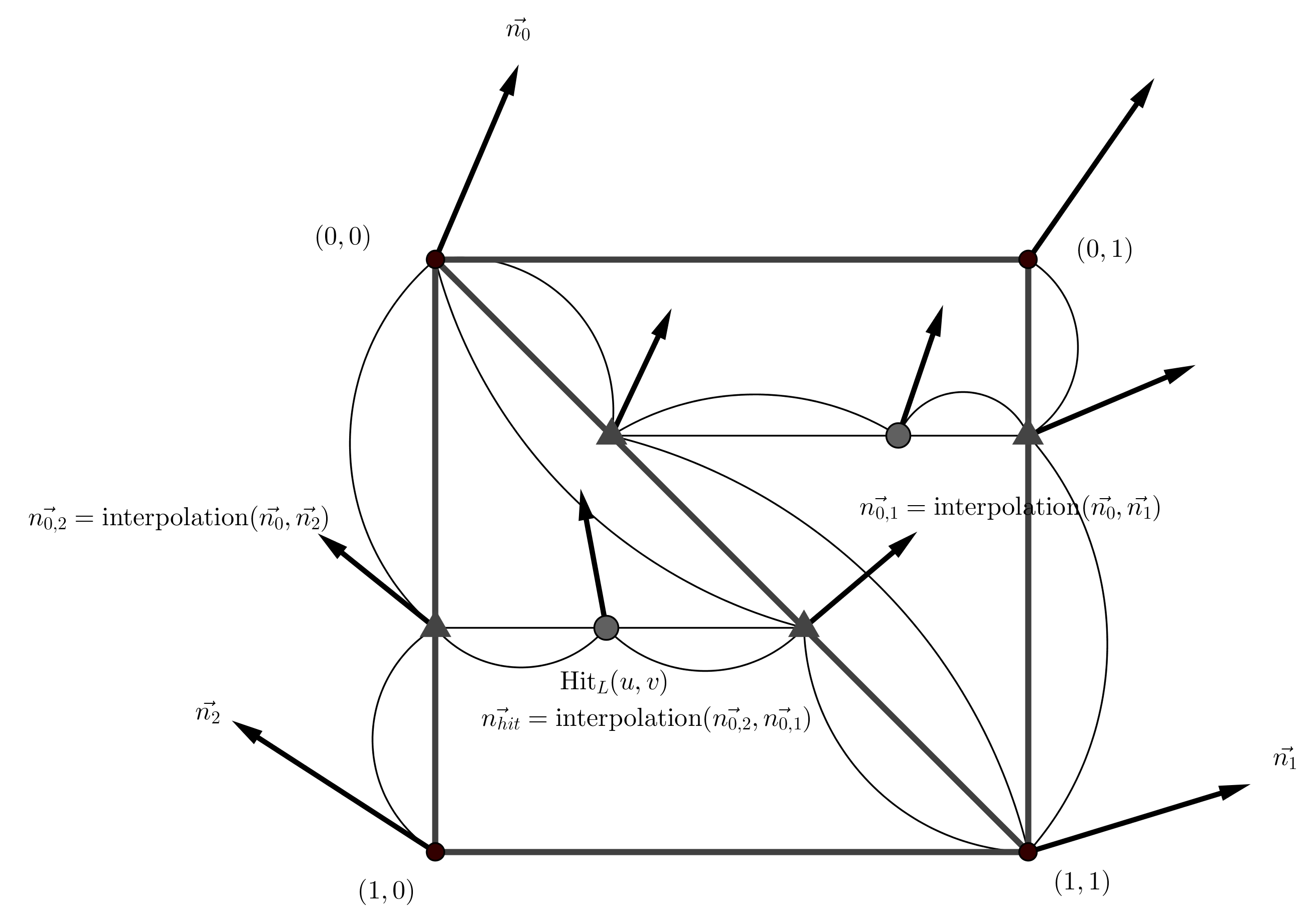
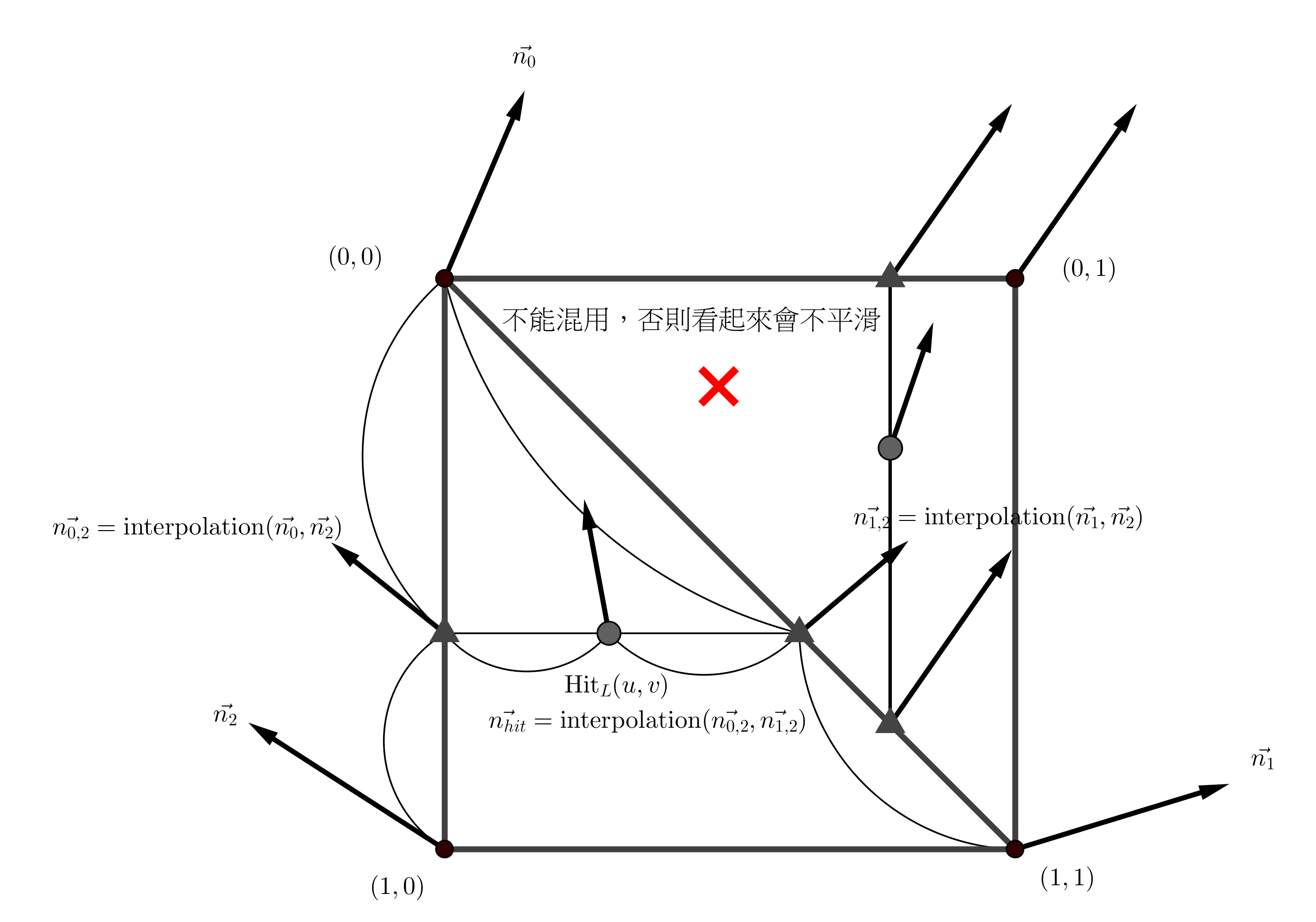
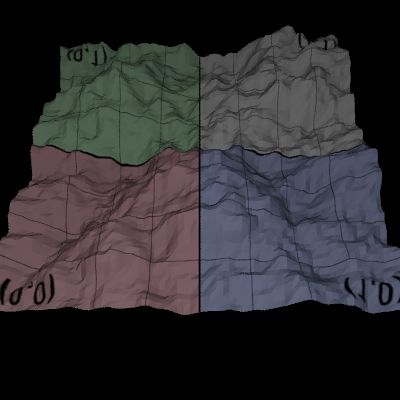
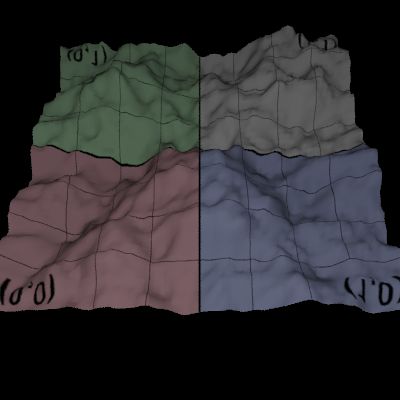
#include <bits/stdc++.h> using namespace std; void method0(int n, int m) { printf("In %s\n", __func__); int bsz = n/m, rm = n%m, sz; for (int i = 0, L = 0, R; i < m; i++) { sz = bsz + (i < rm); R = L + sz - 1; printf("%d len([%d, %d]) = %d\n", i, L, R, (R - L + 1)); L = R + 1; } } void method1(int n, int m) { printf("In %s\n", __func__); for (int i = 0, L, R; i < m; i++) { L = i*n/m, R = (i+1)*n/m - 1; printf("%d len([%d, %d]) = %d\n", i, L, R, (R - L + 1)); } } void method2(int n, int m) { printf("In %s\n", __func__); for (int i = 0, L = 0, R, sz; i < m; i++) { sz = (n + m-i-1) / m; R = L + sz-1; printf("%d len([%d, %d]) = %d\n", i, L, R, sz); L = R + 1; } } void method3(int n, int m) { printf("In %s\n", __func__); for (int i = 0, L = 0, R, sz; i < m; i++) { sz = (n + i) / m; R = L + sz-1; printf("%d len([%d, %d]) = %d\n", i, L, R, sz); L = R + 1; } } void method4(int n, int m) { printf("In %s\n", __func__); int bsz = (n + m-1)/m, sz; for (int i = 0, L = 0, R; i < m; i++) { L = i*bsz, R = L + bsz - 1; if (R >= n) R = n-1; printf("%d len([%d, %d]) = %d\n", i, L, R, (R - L + 1)); } } int main() { void (*FUNC[])(int, int) = {method0, method1, method2, method3, method4}; int n, m; while (scanf("%d %d", &n, &m) == 2) { for (int i = 0; i < sizeof(FUNC)/sizeof(FUNC[0]); i++) (*FUNC[i])(n, m); } return 0; }
|