Least Recently Used Algorithm (LRU) 以 “最近不常使用的 Page Page” 視為Victim Page。
緣由:LRU製作成本過高
作法:
Second econd Chance ( 二次機會法則 )
Enhance nhance Second Chance ( 加強式二次機會法則 )
有可能退化成 FIFO FIFO,會遇到 Belady 異常情況
Second Chance (二次機會法則) 以 FIFO 法則為基礎,搭配 Reference Bit 使用,參照過兩次以上的 page 將不會被置換出去,除非全部都是參照兩次以上,將會退化成 FIFO。
Enhance Second Chance (加強式二次機會法則) 使用(Reference Bit Bit, Modification Bit Bit) 配對值作為挑選 Victim Page 的依據。對於沒有沒修改的 page 優先被置換,減少置換的成本。
Belady’s anomaly 當 Process 分配到較多的 Frame 數量,有時其 Page Fault Ratio 卻不降反升。
Rank
Algorithm
Suffer from Belady’s anomaly
1
Optimal
no
2
LRU
no
3
Second-chance
yes
4
FIFO
yes
Thrashing(振盪)
當 CPU 效能低時,系統會想引入更多的 process 讓 CPU 盡可能地工作。但當存有太多 process 時,大部分的工作將會花費在 page fault 造成的 Page Replacement,致使 CPU 效率下降,最後造成 CPU 的效能越來越低。
解決方法
[方法 1] 降低 Multiprogramming Degree。
[方法 2] 利用 Page Fault Frequency (Ratio) 控制來防止 Thrashing。
[方法 3] 利用 Working Set Model “預估 ” 各 Process 在不同執行時期所需的頁框數,並依此提供足夠的頁框數,以防止 Thrashing。
作法 OS 設定一個Working Set Window (工作集視窗;Δ) 大小,以Δ 次記憶體存取中,所存取到的不同Page之集合,此一集合稱為 Working Set 。而Working Set中的Process個數,稱為 Working Set Size ( 工作集大小; WSS) 。
Page
Page Size 愈小
缺點
Page fault ratio愈高
Page Table Size愈大
I/O Time (執行整個Process的I/O Time) 愈大
優點
內部碎裂愈小
Total I/O Time (單一Page的Transfer Time) 愈小
Locality愈集中
Fragmentation
分成外部和內部碎裂 External & Internal Fragmentation
Deadlock(死結)
成因
mutual exclusion 資源互斥 一個資源只能分配給一個 process,不能同時分配給多個 process 同時使用。
hold-and-wait 擁有並等待 擁有部分請求的資源,同時等待別的 process 所擁有資源
no preemption 不可搶先 不可搶奪別的 process 已經擁有的資源
circular wait 循環等待 存有循環等待的情況
解決方法
Dead Lock Prevention 不會存有死結成因四條中的任何一條。
Dead Lock Avoidance 對運行的情況做模擬,找一個簡單的算法查看是否有解死結,但這算法可能會導致可解的情況,歸屬在不可解的情況。
Use a. to get: $\sum Need + \sum Allocation < m + n$
Use c. to get: $\sum Need_{i} + m < m + n$
Rewrite to get: $\sum Need_{i} < n$
Dead Lock Detection & Recovery Recovery 成本太高
小問題
Propose two approaches to protect files in a file system. 檔案系統如何保護檔案?請提供兩種方式。
對檔案做加密動作,或者將檔案藏起-不可讀取。
The system will enter deadlock if you cannot find a safe sequence for it, YES or NO? Please draw a diagram to explain your answer. 如果找不到一個安全序列,是否就代表系統進入死結?
多個為了不增加工作量,這裡就沒有親自去實作。某方面來說,可能要寫很多 small program 進行測試,並且撰寫時還要預測會跑多久,這難度會稍微提高。
第二種方式按照軟工的寫法 來寫 test code 吧!如果細心一點,就會看到相關的 Class::SelfTest() 在很多 class 都有的,因此我們需要把 test code 寫到 SelfTest 中被呼叫。因此,不需要有實體的 process 運行,只是單純地測試我們寫的 scheduler 的排程順序是否正確。
在 Burst Time 計算上,如果採用運行時估計,可以在以下代碼中進行計算。kernel->stats->userTicks 是執行 user program 的時間累加器 (也存有一個 system program 的時間累加器,運行 thread context-free, thread scheduling … 等時間用途。)
What is multiprogramming ? what is time-sharing ?(10%)
Multiprogramming(多重程式):
定義: 內存有多個 processs 同時執行,一般電腦的運行方式。透過 CPU scheduling 將發生中斷 (eg. wait for I/O complete, resource not available, etc.) 的行程切換給可執行的運作。
特色: 可以避免 CPU idle,提高 CPU utilization(使用率)
其他:
Multiprogramming Degree:系統內存在執行的 process 數目
通常 Multiprogramming Degree 越高,則 CPU utilization 越高(p.s. ch7 Thrashing 除外)
多個 process 同時執行,mode 有兩種 Concurrent(並行)、Parallel(平行)
Time-sharing:
定義: Multiprogramming 的一種,在 CPU 排班法則方面,其使用 RR(Round-Robin) 法則。 // RR 法則-CPU time quantum,若 process 在取得 CPU 後,未能於 quantum // 內完成工作,則必須被迫放棄 CPU,等待下一次輪迴。
特色: 對每個 user 皆是公平的,適用在 user interactive 且 response time (反應時間)要求較短的系統環境,透過 resource sharing 技術(eg. CPU scheduling, memory sharing, spooling 達到 I/O Device 共享),使得每個user皆認為有專屬的系統存在。
Describe the differences between symmetric and asymmetric multiprocessing. What are three advantages and one disadvantage of multiprocessor systems ? In Distributed System - Multiprocessor - Tightly-Coupled System(different from Loosely-Coupled Distributed System)
What are the differences between a trap and an interrupt? What is the use of each function ?
Trap: 軟體產生 system call an exception in a user process. ex. system call (software divide-by-zero)
Interrupt: 硬體產生 signal something generated by the hardware. ex. IO-complete interrupt (hardware generated)
兩者相同之處 從 User Mode 切換到 Kernel Mode。 兩者都算是 interrupt 中斷指令。
What is the purpose of system calls? System calls allow user-level processes to request services of the operating system. System calls 提供 使用者級別 的程序來請求作業系統給的服務。 // process control, file Management, device management, information maintenance, communication
Describe the differences among short-term, medium-term, and long-term scheduling.
short-term (CPU scheduler) — CPU 工作排程 selects from jobs in memory those jobs that are ready to execute and allocates the CPU to them.
medium-term — 常用於分時系統的排程器。當記憶體不夠的時候,需要暫時將部分的執行程序搬出,將新來的程序載入,置換機制被建置用來移除部份在記憶體執行中及恢復那些被暫時移除的程式。 used especially with time-sharing systems as an intermediate scheduling level. A swapping scheme is implemented to remove partially run programs from memory and reinstate them later to continue where they left off.
long-term (job scheduler) — 將 job 變成 process 的工作排程,將工作從硬碟載入到主記憶體中。 determines which jobs are brought into memory for processing.
Can a multithreaded solution using multiple user-level threads achieve better performance on a multiprocessor system than on a single-processor system? Why?
A multithreaded system comprising of multiple user-level threads cannot make use of the different processors in a multiprocessor system simultaneously. The operating system sees only a single process and will not schedule the different threads of the process on separate processors. Consequently, there is no performance benefit associated with executing multiple user-level threads on a multiprocessor system.
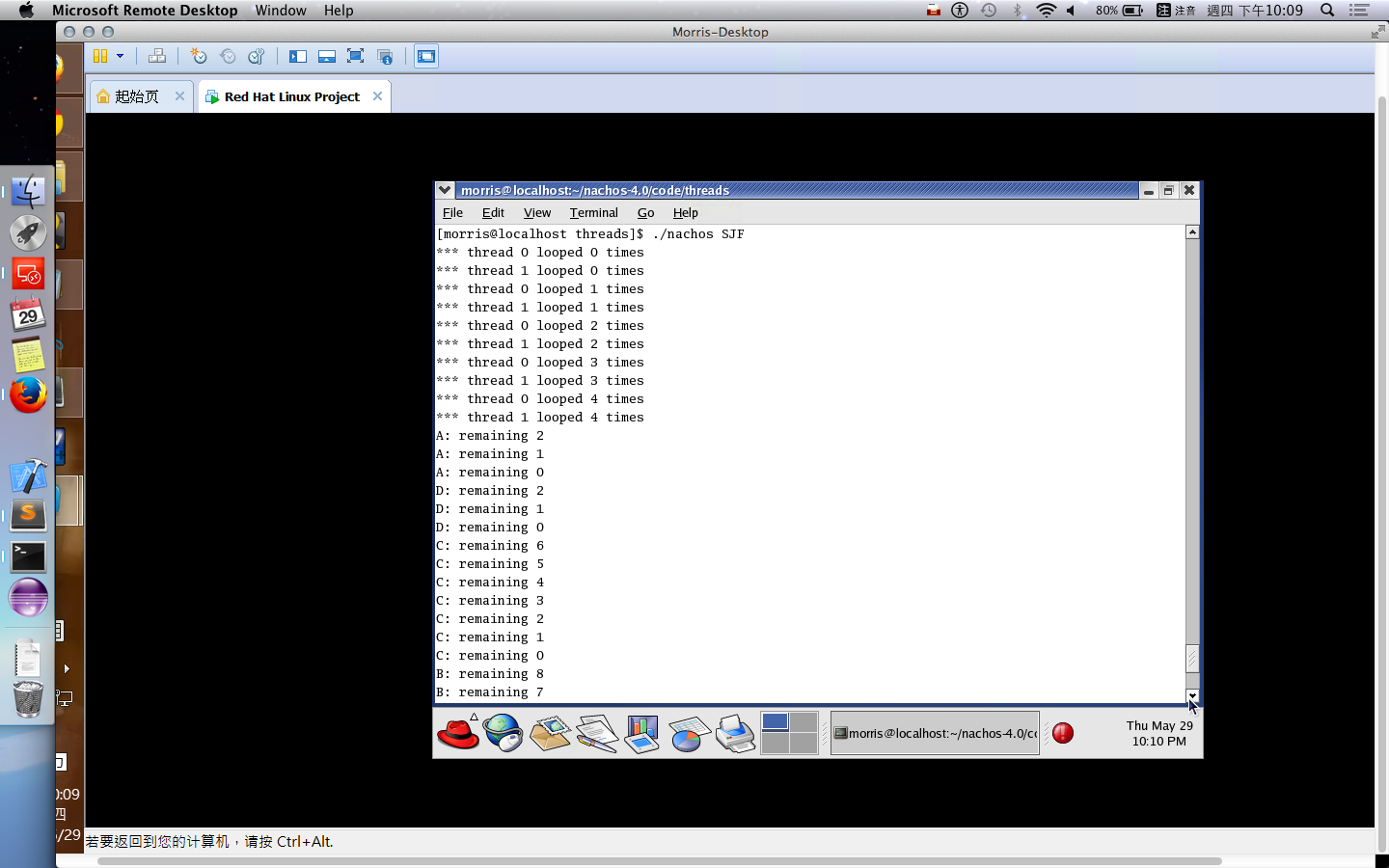
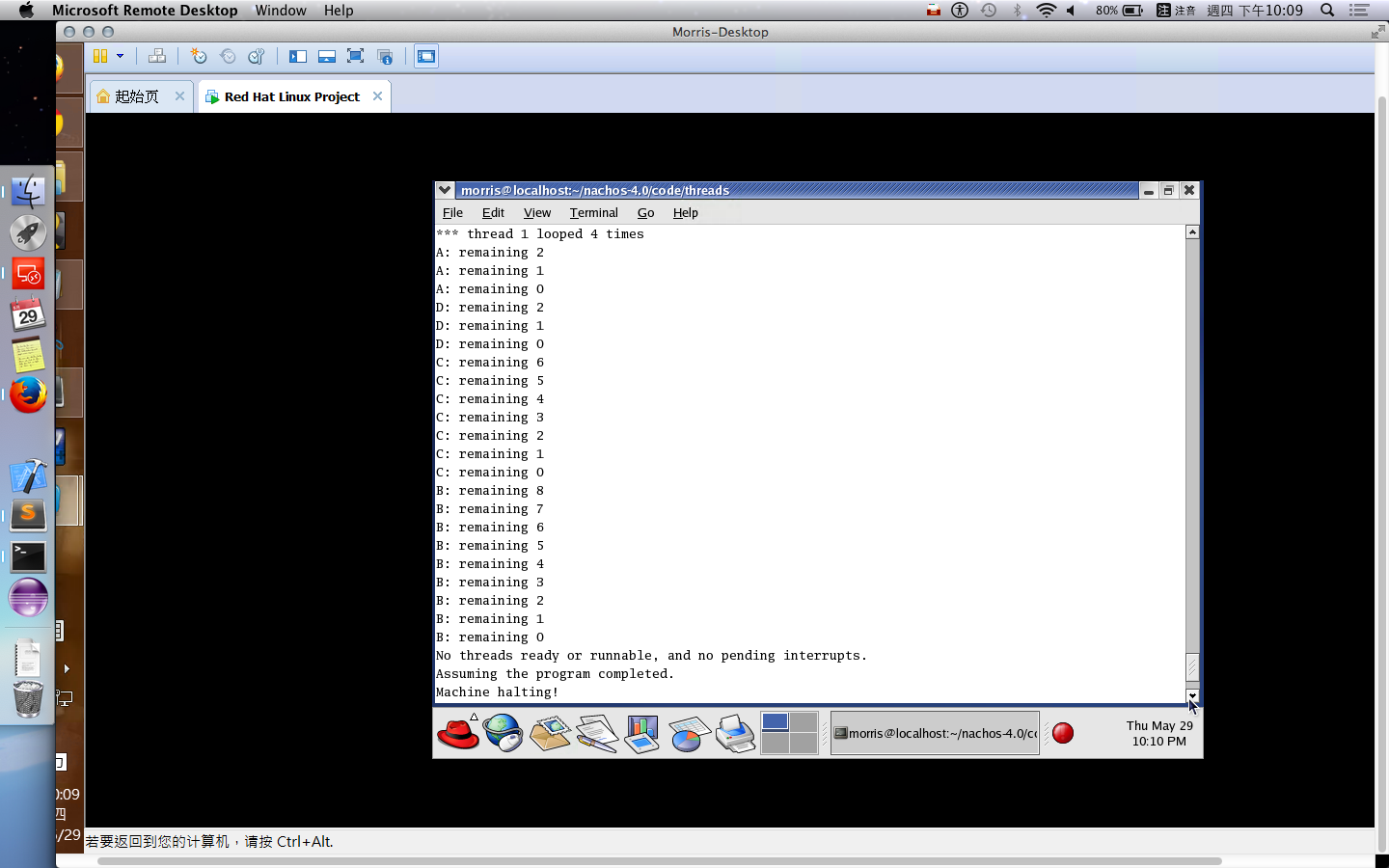
Consider the following set of processes, with the length of the CPU-burst time given in milliseconds:
Process Burst Time Priority
P1 10 3
P2 1 1
P3 2 3
P4 1 4
P5 5 2
The processes are assumed to have arrived in the order P1,P2,P3,P4,P5, all at time 0.
(a) Draw four Gantt charts illustrating the execution of these processes using FCFS, SJF, a nonpreempitive priority(a small priority number implies a higher priority), and RR(quantum = 1) scheduling.(5%)
(b) What is the turnaround time of each process for each of the scheduling algorithms in part(a).(5%)
(c) What is the waiting time of each process for each of the scheduling algorithms in part(a).(5%)
(d) Which of the schedules in part (a) results in the minimal average waiting time(over all processes)? (5%)
請參照上附的習題解法。
96 期中考
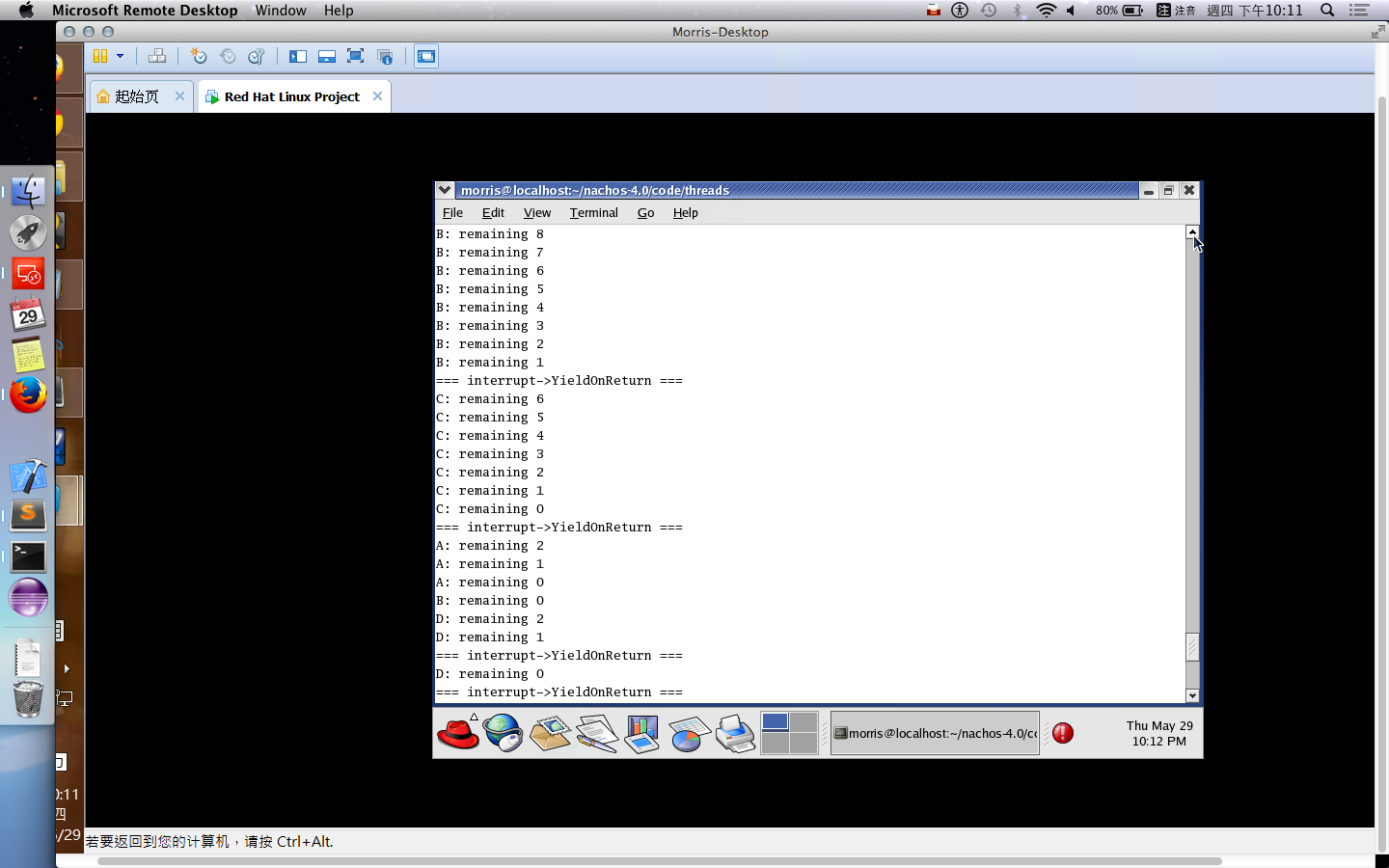
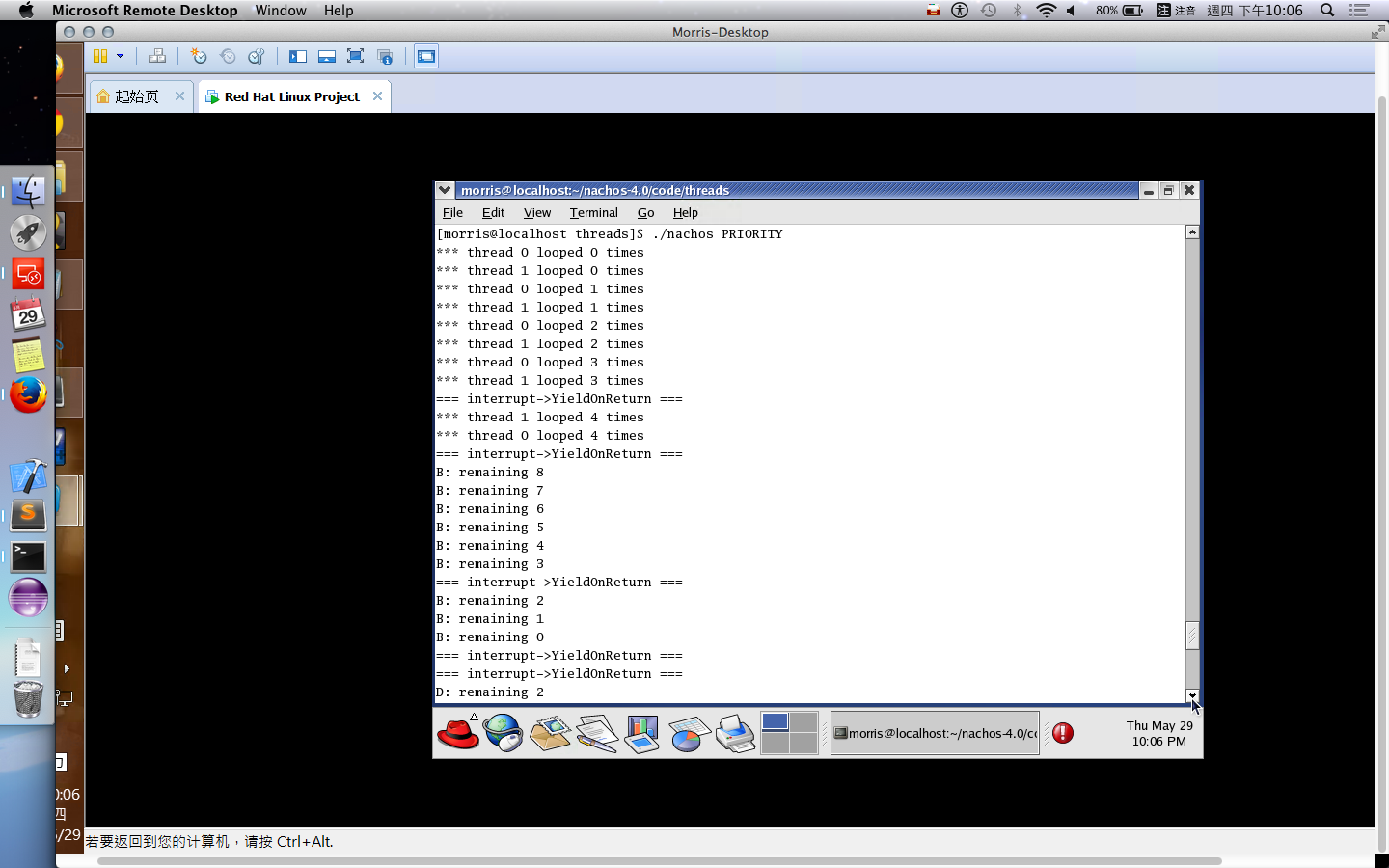
FCFS, SJF, Priority, Round-Robin and Multilevel Queue Which can be preemptive ? (5%)
What is Multilevel Feedback-Queue scheduling ? (5%)
定義:
與Multilevel Queue的定義相似,差別在於允許 Process 在各佇列之間移動 ,以避免Starvation 的情況。
* 採取類似 “Aging” 技術,毎隔一段時間就將 Process 往上提升到上一層 Queue 中。∴在經過有限時間後,在 Lower Priority Queue 中的 Process 會被置於 Highest Priority Queue 中。故無 Starvation。
* 亦可配合降級之動作。當上層 Queue 中的 Process 取得 CPU 後,若未能在 Quantum 內完成工作,則此 Process 在放棄 CPU 後,會被置於較下層的 Queue 中。
Please draw the Gantt charts for the following processes for the problems shown below. (a) Round-Robinm time quantum = 1 (5%) (b) Shortest-remaining-time-first (Preemptive SJF) (5%)
5.9 Why is it important for the scheduler to distinguish I/O-bound programs from CPU-bound programs? 為什麼排程器需要需分 IO 密集程式 和 CPU 綁定程式 ?
Answer: I/O-bound programs have the property of performing only a small amount of computation before performing I/O. Such programs typically do not use up their entire CPU quantum. CPU-bound programs, on the other hand, use their entire quantum without performing any blocking I/O operations. Consequently, one could make better use of the computer’s resouces by giving higher priority to I/O-bound programs and allow them to execute ahead of the CPU-bound programs. IO 密集程式占用 CPU 的時間比較少,大部分時間等在等待 IO。相反地 CPU 綁定程式則會大幅度占用 CPU 的時候,因為沒有 IO 操作的堵塞。
而 CPU bound 的程序因此而得到了很多調度機會並且每次都能把CPU run完。故在這樣的系統裡要給 I/O bound 的程序更高的優先級使其能被調度得更多些。
5.10 Discuss how the following pairs of scheduling criteria conflict in certain settings. a. CPU utilization and response time // CPU 使用率 和 回應時間 的比較 b. Average turnaround time and maximum waiting time // 平均運轉時間 和 最大等待時間 的比較 c. I/O device utilization and CPU utilization // IO 裝置使用率 和 CPU 使用率 的比較
Answer: a. CPU utilization and response time: CPU utilization is increased if the overheads associatedwith context switching isminimized. The context switching overheads could be lowered by performing context switches infrequently. This could, however, result in increasing the response time for processes. CPU 的使用率(utilization)上升時,切換工作的次數(context-switches)就會少,由於切換次數少,則回應時間(response time)就會上升。
b. Average turnaround time and maximum waiting time: Average turnaround time is minimized by executing the shortest tasks first. Such a scheduling policy could, however, starve long-running tasks and thereby increase their waiting time. 平均運作時間(average turnaround time) 的最小化可以藉由最短工作優先的方式,但是這將會使得長工作飢餓,如此會增加最大等待時間。
c. I/O device utilization and CPU utilization: CPU utilization is maximized by running long-running CPU-bound tasks without performing context switches. I/O device utilization is maximized by scheduling I/O-bound jobs as soon as they become ready to run, thereby incurring the overheads of context switches. CPU 使用率的上升盡可能讓 CPU 密集工作長時間運行 (減少 IO 或者其他的中斷所引發的上下文切換),IO 裝置使用率的上升靠的是讓排入的 IO 密集工作立即地運行,但這會增加上下文切換的開銷。
5.11 Consider the exponential average formula used to predict the length of the next CPU burst.What are the implications of assigning the following values to the parameters used by the algorithm? 使用指數平均公式去預測下一次的 CPU burst。 t0 預估時間。 a. a = 0 and t0 = 100 milliseconds b. a = 0.99 and t0 = 10 milliseconds
Answer: When a = 0 and t0 = 100 milliseconds, the formula always makes a prediction of 100 milliseconds for the next CPU burst. When a = 0.99 and t0 = 10 milliseconds, themost recent behavior of the process is given much higher weight than the past history associated with the process. Consequently, the scheduling algorithm is almost memoryless, and simply predicts the length of the previous burst for the next quantum of CPU execution. 當 a = 0 時,預測的時間總會是 100 milliseconds,而當 a = 0.99 時,將會高度依賴近期幾次的結果,而對於歷史關聯只有較輕的權重。 // t(n+1) = a * 上一次實際時間 + (1 - a) * t(n)