contents
序文
相較於其他技術而言,編譯器的確不是什麼有趣的課程,在這一門領域專研的人也變少了,所以專精的人越少,將會越有機會。易見地,也越來越少大學開設這門編譯器的課程,不過在一些公司,編譯器的技術將成為私囊秘寶,如何將代碼更加地優化快速,這就是相當令人感到為之一驚的地方。
DFA, NFA, Regular expression
在討論所有語法前,要明白正規表達式 ( Regular expression = RegExp ) 的運作,RegExp 運作上涵蓋的語法集合是最小的,對於一個 RegExp 來說,可以轉換成具有 n 個狀態的 NFA,而這台 NFA 可以轉換成 2n 狀態的 DFA。
NFA 和 DFA 最大的不同在於轉移狀態時,考慮的路徑情況,NFA 可以在不考慮輸入進行轉移,或者在相同情況下可以有很多轉移選擇。 DFA 則必須在一個輸入唯一一個轉移情況下運作。

如上圖 DFA 所示,邊上的內容就是根據輸入的情況進行轉移。

如上圖 NFA 所示,會發現狀態 p 對於輸入 1 有 2 種轉移可能 (p->p or p->q)。
最後可以得到一個 RegExp 一定會有一台 DFA 辨識它。而一台 DFA 也一定會有一個 RegExp,這句話的含意將可以在 計算理論 這門課中學到如何藉由類似 Floyd Algorithm 內點性質依序推出 DFA 對應的 RegExp。
CFG (Context-free grammar)
A context-free grammar is a formal system that describes a language by specifying how any legal string (i.e., sequence of tokens) can be derived from a start symbol. It consists of a set of productions, each of which states that a given symbol can be replaced by a given sequence of symbols.
另一個類似的語言是 Context-sensitive grammar,等價性質的兄弟是 Chomsky normal form。
CFG
G = (Vt, Vn, S, P)- Vt: 有限的 terminal 字符集
- Vn: 有限的 nonterminal 字符集
- S: 一開始出發的 start symbol
- P: 轉換的規則 (production)
來個例子
LHS (left-hand side) -> RHS (right-hand side) <E> -> <Prefix> ( <E> ) <E> -> V <Tail> <Prefix> -> F <Prefix> -> l <Tail> -> + <E> <Tail> -> l明顯地
Vt = {(, ), V, F, l, +}Vn = {<E>, <Prefix>, <Tail>}S = <E>P就是給定那六條規規則
- 名詞
- Sentential form
If S =>* β, β then is said to be sentential form of the CFG
簡單來說,所有從 start symbol 過程中替換出來的句子都稱為 sentential form。 - Handle of a sentential form
The handle of a sentential form is the left-most simple phrase.
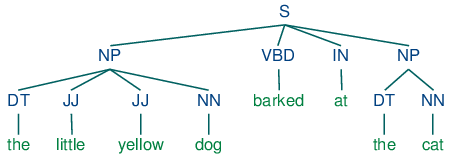
簡單來說,就是將一個 nonterminal 根據 production 轉換成 RHS (right-hand side) 的一個步驟。
- Sentential form
- 什麼是 CFG (上下文無關語法)?
簡單來說,還真的是上下文無關,例如S -> AB可以見到 S 轉換時,不會因為前文或後文是什麼內容而影響,而在Context-sensitive grammar(上下文敏感) 可以見到aSb -> AB會因為前面跟後面所受到的影響。
這裡使用大寫為 nontermainl,其他字符為 terminal。
First Set
- First(A)
- The set of all the terminal symbols that can begin a sentential form derivable from A.
A =>* aBFirst(A) = { a in Vt | A =>* aB, and Λ in Vt | A =>* Λ } - 簡單地說,從這個 nonterminal 開始,第一個不能被替換的 terminal 就會在 First set 中。
- The set of all the terminal symbols that can begin a sentential form derivable from A.
- 計算
First(A)前,必須先建出這個 nonterminal 有沒有可能推出 Λ,即A =>* Λ。
這邊相當有意思,使用迭代更新,如果發現B =>* Λ和C =>* Λ則對於 ProductionA => BC來說,可以得到A =>* Λ就這麼依序推出所有情況,時間複雜度應該在O(n^2)。 - 計算
First(A)時,掃描規則LHS => RHS,找到First(RHS)並且First(LHS).insert(First(RHS)),依樣使用迭代更新推出所有情況,時間複雜度應該在O(n^2)。
Follow Set
- Follow(A)
- A is any nonterminal
- Follow(A) is the set of terminals that may follow A in some sentential form.
S =>* ... Aabc ...follow set。Follow(A) = { a in Vt | S =>* ... Aa ..., and Λ in Vt | S =>* aA } - 請切記,一定要從 start symbol 開始替換的所有句子,而在這個 nonterminal 隨後可能跟著的 termainl 就會屬於它的。
- 計算
Follow(A)前,請先把 First set 都算完,接著也是用迭代更新,掃描規則A -> a B b
對於1234567891011121314if Λ not in First(b)Follow(B).insert(First(b))elseFollow(B).insert(First(b) - Λ)Follow(B).insert(Follow(A))```## Predict Set ##* Given the productions* During a (leftmost) derivation, Deciding which production to match, Using lookahead symbols* 相較於 First set 和 Follow set,Predict Set 是根據 Production 產生的,也就是說一條 production 會有一個對應的 predict set,而 First set 和 Follow set 都是根據 nonterminal 產生一對一對應的集合,用來預測這一條規則的第一個 terminal 會有哪些。對於 production : `A -> X1 X2 ... Xm`
if Λ in First(X1 X2 … Xm)
Predict(A -> X1 X2 … Xm).insert(First(X1 X2 … Xm) - Λ);
Predict(A -> X1 X2 … Xm).insert(Follow(A));
else
Predict(A -> X1 X2 … Xm).insert(First(X1 X2 … Xm));
S->aSe
S->B
B->bBe
B->C
C->cCe
C->d
A->BaAb
A->cC
B->d
B->l
C->eA
C->l
A->aAd
A->B
B->bBd
B->C
C->cCd
C->l
E->TX
X->+E
X->#
T->(E)
T->intY
Y->*T
Y->#
E->P(E)
E->vT
P->f
P->l
T->+E
T->l
S->aSe
S->B
B->bBe
B->C
C->cCe
C->d
S->ABc
A->a
A->l
B->b
B->l
|
|
B:b,c,d
C:c,d
S:a,b,c,d
a:a
b:b
c:c
d:d
e:e
A:a,c,d
B:d,l
C:e,l
a:a
b:b
c:c
d:d
e:e
A:a,b,c,l
B:b,c,l
C:c,l
a:a
b:b
c:c
d:d
#:#
(:(
):)
:
+:+
E:(,i
T:(,i
X:#,+
Y:#,*
i:i
n:n
t:t
(:(
):)
+:+
E:(,f,v
P:f,l
T:+,l
f:f
v:v
B:b,c,d
C:c,d
S:a,b,c,d
a:a
b:b
c:c
d:d
e:e
A:a,l
B:b,l
S:a,b,c
a:a
b:b
c:c
begin ID := ID - INTLIT + ID ; end $
+—————-+—– First set —–+
|$ | { $ }
|( | { ( }
|) | { ) }
|+ | { + }
|, | { , }
|- | { - }
|:= | { := }
|; | { ; }
|
|
|
|
|
|
|
|
|
|
|
|
|
|ID | { ID }
|INTLIT | { INTLIT }
|begin | { begin }
|end | { end }
|read | { read }
|write | { write }
+—————-+———————+
+—————-+—– Follow set —–+
|
|
|
|
|
|
|
|
|
|
|
|
|
+—————-+———————+
+—————-+—– LL(1) table —–+
| | $| (| )| +| ,| -| :=| ;| ID|INTLIT| begin| end| read| write|
|
|
|
|
|
|
|
|
|
|
|
|
|
+—————-+———————+
Process syntax accept
```
代碼
2014/6/1 修正 parsing 時的 lambda 問題。
|
|
備註
要學會更多,請修 計算理論 這門課程。